IPython-powered Slideshow Reveal-ed
A good rule about present talks says:
DON'T DEMO
BUT...
I WILL NOT FOLLOW IT.
INTRO...
"A long time ago in a galaxy far, far away..."
January 2012, +Wes McKinney (@wesmckinn) said in twitter:
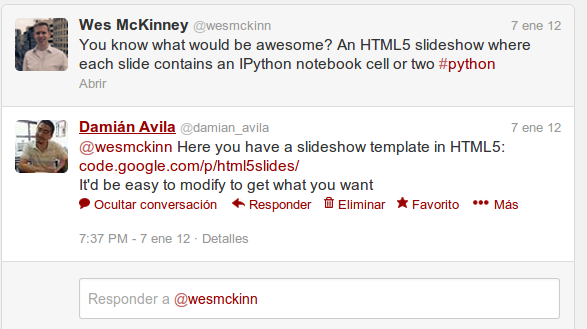
Resume I:
- I embedded the IPython notebook in a HTML slideshow...
- I use an iframe-based approach...
- Too much hacky...

Resume II:
- Interesting...
- Presentation materials from notebook is high in our to do list...
- Streamline the process...

NBCONVERT
Conversion utilities for the IPython notebook format
IPYNB to HTML was supported (this is the heart of nbviewer service).
Maybe...
I could write a converter for IPYNB to a html-based slideshow.

The aim was:
Easily get a html5/css-based slideshows directly from IPython notebook.
This slideshow (obviously) is IPython/Reveal.js-powered.
(Remember, DON'T DEMO, hehe)...
So... are you ready?!
Here we go...
Ingredients:
IPython Slideshow UI
Open a new notebook (or a previous one) and you will see the IPython toolbar containing a new Cell Toolbar drowdown menu that give you access to metadata for each cell.

If you select the Slideshow preset, you will see in the right corner of each cell a little box:
a dropdown menu with the following labels:
- -
- Slide
- Sub-Slide
- Fragment
- Skip
- Notes
Let me show you the live notebook...
Slides
Slides are just slides, they are horizontally aligned... you have seen them before.
OK, I am lying to you a little bit...
Slides are the main logical unit of information in this slideshow framework.
And they encompass all the other labels.
To navigate them just go backward with left arrow or go forward with right arrow.
Sub-Slides
Sub-slides are vertically aligned slides (you have seen them before too).
They belong to a greater group: a Slide.
So, you must add a new Sub-Slide after a previous cell labelled as Slide.
Then you can add more Sub-Slides if you want and will be rendered as vertically aligned slides until you label a new cell as Slide.
To navigate them just use the down arrow or up arrow.
Test it now...
Test Sub-Slide 1 level
Have you notice the controller at the bottom right of the slide?
You can navigate with it, if you want (I prefer the keyboard) but it also indicates in which direction you have new Slides or Sub-Slides (darker arrows).
Please go down one more time.
Test Sub-Slide 2 level
You also have a progression bar at the bottom of the slideshow (blue line) to keep an indication of how many slides have been shown and how many we got ahead.
Fragments
Now we began with some intra-slides properties.
A Fragment lives inside a Slide or Subslide and it is constrained at the cell level.
You can have multiple Fragments inside a slide, which will rendered in descending order following the flow of the cells.
Press the right arrow.
- I am a Fragment.
- I am another one.
- And another one.
Skip
If you want to skip some cell, just label it as Skip.
I will be in the final html slideshow source but it will not be rendered in your browser.
Just let me show you the notebook again...
Notes
We provided speaker notes through the Notes label.
These cells will not be rendered by your browser inside the main slideshow window.
You want to test it?
Just press "s" in you keyboard and you will see a new emerging window containing the current slide, the next one, a simple timer and, finally, the notes.
Do nothing cell, just render it: -
I think this does not need further explanation.
Ahh... I am a "-" cell.
And now... the reveal magic begins.
After labelling properly the cells in your notebook, you save it (do not forget it!) and you are ready to do the next step.
First of all, after cloning the nbconvert master, you have to download (or clone) the reveal library and move it into the same folder where your_slideshow.ipynb lives.
Copy your your_slideshow.ipynb inside the nbconvert folder and then:
$ python nbconvert.py reveal your_slideshow.ipynb
Now you have a file: your_slideshow.reveal.html, then serve it:
$ python -m SimpleHTTPServer 8000
Open it and voila!
Note: this is one way to do it (there are many others ways).
NBCONVERT is (NOW) powerful...
Reveal converter in nbconvert1:
%load nbconvert1/converters/reveal.py
from __future__ import absolute_import
from .html import ConverterHTML
from .utils import text_cell
from .utils import highlight, coalesce_streams
from IPython.utils import path
from markdown import markdown
import os
import io
import itertools
class ConverterReveal(ConverterHTML):
"""
Convert a ipython notebook to a html slideshow
based in reveal.js library.
"""
@text_cell
def render_heading(self, cell):
marker = cell.level
return [self.meta2str(cell.metadata),
u'<h{1}>\n {0}\n</h{1}>'.format(cell.source, marker)]
def render_code(self, cell):
if not cell.input:
return []
lines = []
meta_code = self.meta2str(cell.metadata)
lines.extend([meta_code])
lines.extend(['<div class="cell border-box-sizing code_cell vbox">'])
lines.append('<div class="input hbox">')
n = self._get_prompt_number(cell)
lines.append(
'<div class="prompt input_prompt">In [%s]:</div>' % n
)
lines.append('<div class="input_area box-flex1">')
lines.append(highlight(cell.input))
lines.append('</div>') # input_area
lines.append('</div>') # input
if cell.outputs:
lines.append('<div class="vbox output_wrapper">')
lines.append('<div class="output vbox">')
for output in coalesce_streams(cell.outputs):
conv_fn = self.dispatch(output.output_type)
lines.extend(conv_fn(output))
lines.append('</div>') # output
lines.append('</div>') # output_wrapper
lines.append('</div>') # cell
return lines
@text_cell
def render_markdown(self, cell):
return [self.meta2str(cell.metadata), markdown(cell.source)]
def render_raw(self, cell):
if self.raw_as_verbatim:
return [self.in_tag('pre', self.meta2str(cell.metadata)),
self.in_tag('pre', cell.source)]
else:
return [self.meta2str(cell.metadata), cell.source]
def meta2str(self, meta):
"transform metadata dict (containing slides delimiters) to string "
try:
meta_tuple = meta[u'slideshow'].items()
except KeyError as e: # if there is not slideshow metadata
meta_tuple = [(u'slide_type', u'untouched')]
meta_list = [[x + ' = ' + unicode(y)] for x, y in meta_tuple]
return u'\n'.join(list(itertools.chain(*meta_list)))
def convert(self, cell_separator='\n'):
"""
Specific method to converts notebook to a string representation.
Parameters
----------
cell_separator : string
Character or string to join cells with. Default is "\n"
Returns
-------
out : string
"""
lines = []
lines.extend(self.optional_header())
begin = ['<div class="reveal"><div class="slides">']
lines.extend(begin)
slides_list = self.build_slides()
lines.extend(slides_list)
end = ['</div></div>']
lines.extend(end)
lines.extend(self.optional_footer())
return u'\n'.join(lines)
def clean_text(self, cell_separator='\n'):
"clean and reorganize the text list to be slided"
text = self.main_body(cell_separator)
self.delim = [u'slide_type = untouched',
u'slide_type = -',
u'slide_type = slide',
u'slide_type = subslide',
u'slide_type = fragment',
u'slide_type = notes',
u'slide_type = skip'] # keep this one the last
text_cell_render = \
u'<div class="text_cell_render border-box-sizing rendered_html">'
for i, j in enumerate(text):
if j in self.delim and text[i - 1] == text_cell_render:
if j == self.delim[0]:
text[i - 1] = self.delim[0]
elif j == self.delim[1]:
text[i - 1] = self.delim[1]
elif j == self.delim[2]:
text[i - 1] = self.delim[2]
elif j == self.delim[3]:
text[i - 1] = self.delim[3]
elif j == self.delim[4]:
text[i - 1] = self.delim[4]
elif j == self.delim[5]:
text[i - 1] = self.delim[5]
else:
text[i - 1] = self.delim[6]
text[i] = text_cell_render
return text
def build_slides(self):
"build the slides structure from text list and delimiters"
text = self.clean_text()
left = '<section>'
right = '</section>'
notes_start = '<aside class="notes">'
notes_end = '</aside>'
#encapsulation of skipped cells
for i, j in enumerate(text):
if j == u'slide_type = skip':
text.pop(i)
text[i] = text[i][:4] + \
' style=display:none' + text[i][4:]
#encapsulation of notes cells
for i, j in enumerate(text):
if j == u'slide_type = notes':
text.pop(i)
temp_list = []
while not text[i] in self.delim[:6]:
temp_list.append(text.pop(i))
else:
temp_list.insert(0, notes_start)
temp_list.append(notes_end)
text[i:i] = temp_list
# elimination of none names
for i, j in enumerate(text):
if j in [u'slide_type = untouched', u'slide_type = -']:
text.pop(i)
#generation of slides as a list of list
slides = [list(x[1]) for x in itertools.groupby(text,
lambda x: x == u'slide_type = slide') if not x[0]]
for slide in slides:
slide.insert(0, left)
slide.append(right)
# encapsulation of each fragment
for i, j in enumerate(slide):
if j == u'slide_type = fragment':
slide.pop(i)
slide[i] = slide[i][:4] + \
' class="fragment"' + slide[i][4:]
# encapsulation of each nested slide
if u'slide_type = subslide' in slide:
slide.insert(0, left)
slide.append(right)
for i, j in enumerate(slide):
if j == u'slide_type = subslide':
slide[i] = right + left
return list(itertools.chain(*slides))
def render(self):
"read, convert, and save self.infile"
if not hasattr(self, 'nb'):
self.read()
self.output = self.convert()
assert(type(self.output) == unicode)
return self.save()
def save(self, outfile=None, encoding=None):
"read and parse notebook into self.nb"
if outfile is None:
outfile = self.outbase + '_slides.' + 'html'
if encoding is None:
encoding = self.default_encoding
with io.open(outfile, 'w', encoding=encoding) as f:
f.write(self.output)
return os.path.abspath(outfile)
def header_body(self):
"return the body of the header as a list of strings"
from pygments.formatters import HtmlFormatter
header = []
static = os.path.join(path.get_ipython_package_dir(),
'frontend', 'html', 'notebook', 'static',)
here = os.path.split(os.path.realpath(__file__))[0]
css = os.path.join(static, 'css')
for sheet in [
# do we need jquery and prettify?
# os.path.join(static, 'jquery', 'css', 'themes', 'base',
# 'jquery-ui.min.css'),
# os.path.join(static, 'prettify', 'prettify.css'),
os.path.join(css, 'boilerplate.css'),
os.path.join(css, 'style.min.css'),
# our overrides:
os.path.join(here, '..', 'css', 'reveal_html.css'),
]:
header.extend(self._stylesheet(sheet))
# pygments css
pygments_css = HtmlFormatter().get_style_defs('.highlight')
header.extend(['<meta charset="UTF-8">'])
header.extend(self.in_tag('style', pygments_css,
dict(type='"text/css"')))
return header
def template_read(self, templ):
"read the reveal_template.html"
here = os.path.split(os.path.realpath(__file__))[0]
reveal_template = os.path.join(here, '..', 'templates',
templ)
with io.open(reveal_template, 'r', encoding='utf-8') as f:
template = f.readlines()
template = [s.strip() for s in template]
return template
def template_split(self):
"split the reveal_template.html in header and footer lists"
temp = self.template_read('reveal_base.html')
splitted_temp = [list(x[1]) for x in itertools.groupby(temp,
lambda x: x == u'%slides%') if not x[0]]
return splitted_temp
def optional_header(self):
optional_header_body = self.template_split()
return ['<!DOCTYPE html>', '<html>', '<head>'] + \
optional_header_body[0] + self.header_body() + \
['</head>', '<body>']
def optional_footer(self):
optional_footer_body = self.template_split()
return optional_footer_body[1] + ['</body>', '</html>']
Reveal helper and exporter (in the new NBCONVERT)
%load nbconvert/transformers/revealhelp.py
"""Module that pre-processes the notebook for export via Reveal.
"""
#-----------------------------------------------------------------------------
# Copyright (c) 2013, the IPython Development Team.
#
# Distributed under the terms of the Modified BSD License.
#
# The full license is in the file COPYING.txt, distributed with this software.
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# Imports
#-----------------------------------------------------------------------------
from .base import ConfigurableTransformer
#-----------------------------------------------------------------------------
# Classes and functions
#-----------------------------------------------------------------------------
class RevealHelpTransformer(ConfigurableTransformer):
def call(self, nb, resources):
"""
Called once to 'transform' contents of the notebook.
Parameters
----------
nb : NotebookNode
Notebook being converted
resources : dictionary
Additional resources used in the conversion process. Allows
transformers to pass variables into the Jinja engine.
"""
for worksheet in nb.worksheets :
for i, cell in enumerate(worksheet.cells):
#Make sure the cell has slideshow metadata.
cell.metadata.align_type = cell.get('metadata', {}).get('slideshow', {}).get('align_type', 'Left')
cell.metadata.slide_type = cell.get('metadata', {}).get('slideshow', {}).get('slide_type', '-')
#Get the slide type. If type is start of subslide or slide,
#end the last subslide/slide.
if cell.metadata.slide_type in ['slide']:
worksheet.cells[i - 1].metadata.slide_helper = 'slide_end'
if cell.metadata.slide_type in ['subslide']:
worksheet.cells[i - 1].metadata.slide_helper = 'subslide_end'
return nb, resources
%load nbconvert/exporters/reveal.py
"""
Reveal slide show exporter.
"""
#-----------------------------------------------------------------------------
# Copyright (c) 2013, the IPython Development Team.
#
# Distributed under the terms of the Modified BSD License.
#
# The full license is in the file COPYING.txt, distributed with this software.
#-----------------------------------------------------------------------------
#-----------------------------------------------------------------------------
# Imports
#-----------------------------------------------------------------------------
from IPython.utils.traitlets import Unicode
# local import
import basichtml
import nbconvert.transformers.revealhelp
from IPython.config import Config
#-----------------------------------------------------------------------------
# Classes
#-----------------------------------------------------------------------------
class RevealExporter(basichtml.BasicHtmlExporter):
"""
Exports a Reveal slide show (.HTML) which may be rendered in a web browser.
"""
file_extension = Unicode(
'reveal.html', config=True,
help="Extension of the file that should be written to disk")
template_file = Unicode(
'reveal', config=True,
help="Name of the template file to use")
def _register_transformers(self):
"""
Register all of the transformers needed for this exporter.
"""
#Register the transformers of the base class.
super(RevealExporter, self)._register_transformers()
#Register reveal help transformer
self.register_transformer(nbconvert.transformers.revealhelp.RevealHelpTransformer)
@property
def default_config(self):
c = Config({'CSSHtmlHeaderTransformer':{'enabled':True}})
c.merge(super(RevealExporter,self).default_config)
return c
Reveal is powerful...
Themes
You want to see use some another themes? Go here:
These are the "light" themes.
NOTE: To use the "darker" themes, you have to change some css or use my modified themes (yeah, I will upload them to github soon).
We (I... do you want to join me? I would be great!) are working in some more customized themes to provide a proper fit with the notebook-derived slideshows.
Transitions
Some other interesting things...
- You want to get a overview of the slideshow, just press "Esc" and Ctrl+/- to zoom in and zoom out.
- You want to explain some thing, press "b" and your audience will not be distracted.
- You want to get a pdf from your slideshow, with firefox you can get it! More info here.
More Info...
We support only some of the basic functionality provided by reveal... if you want go further, you can go here, get info, and customize some things.
Any question? Ping me: @damian_avila
And now a classical notebook example...
A brief (adapted) tour of the IPython notebook
pwd
ls
message = 'The IPython notebook is great!'
# note: the echo command does not run on Windows, it's a unix command.
!echo $message
Plots with matplotlib
IPython adds an 'inline' matplotlib backend, which embeds any matplotlib figures into the notebook.
%pylab inline
x = linspace(0, 3*pi, 500)
plot(x, sin(x**2))
title('A simple chirp');

You can paste blocks of input with prompt markers, such as those from the official Python tutorial
>>> the_world_is_flat = 1
>>> if the_world_is_flat:
... print "Be careful not to fall off!"
Errors are shown in informative ways:
%run non_existent_file
x = 1
y = 4
z = y/(1-x)
When IPython needs to display additional information (such as providing details on an object via x?
it will automatically invoke a pager at the bottom of the screen:
magic?
Non-blocking output of kernel
If you execute the next cell, you will see the output arriving as it is generated, not all at the end.
import time, sys
for i in range(8):
print i,
time.sleep(0.5)
Clean crash and restart
We call the low-level system libc.time routine with the wrong argument via ctypes to segfault the Python interpreter:
import sys
from ctypes import CDLL
# This will crash a Linux or Mac system; equivalent calls can be made on Windows
dll = 'dylib' if sys.platform == 'darwin' else '.so.6'
libc = CDLL("libc.%s" % dll)
libc.time(-1) # BOOM!!
Markdown cells can contain formatted text and code
You can italicize, boldface
- build
- lists
and embed code meant for illustration instead of execution in Python:
def f(x):
"""a docstring"""
return x**2
Courtesy of MathJax, you can include mathematical expressions both inline: $e^{i\pi} + 1 = 0$ and displayed:
$$e^x=\sum_{i=0}^\infty \frac{1}{i!}x^i$$
Rich displays: include anything a browser can show
In Python, objects can declare their textual representation using the __repr__ method. IPython expands on this idea and allows objects to declare other, richer representations including:
- HTML
- JSON
- PNG
- JPEG
- SVG
- LaTeX
A single object can declare some or all of these representations; all are handled by IPython's display system. This Notebook shows how you can use this display system to incorporate a broad range of content into your Notebooks.
Images
from IPython.display import Image
Image(filename='logo.png')

An image can also be displayed from raw data or a url:
Image(url='http://python.org/images/python-logo.gif')
Embedded vs Non-embedded Images
As of IPython 0.13, images are embedded by default for compatibility with QtConsole, and the ability to still be displayed offline.
Let's look at the differences:
# by default Image data are embedded
Embed = Image( 'http://scienceview.berkeley.edu/view/images/newview.jpg')
# if kwarg `url` is given, the embedding is assumed to be false
SoftLinked = Image(url='http://scienceview.berkeley.edu/view/images/newview.jpg')
# In each case, embed can be specified explicitly with the `embed` kwarg
# ForceEmbed = Image(url='http://scienceview.berkeley.edu/view/images/newview.jpg', embed=True)
Today's image from a webcam at Berkeley, (at the time I created this notebook). This should also work in the Qtconsole. Drawback is that the saved notebook will be larger, but the image will still be present offline.
Embed

Today's image from same webcam at Berkeley, (refreshed every minutes, if you reload the notebook), visible only with an active internet connexion, that should be different from the previous one. This will not work on Qtconsole. Notebook saved with this kind of image will be lighter and always reflect the current version of the source, but the image won't display offline.
SoftLinked

Video
And more exotic objects can also be displayed, as long as their representation supports the IPython display protocol.
For example, videos hosted externally on YouTube are easy to load (and writing a similar wrapper for other hosted content is trivial):
from IPython.display import YouTubeVideo
# a talk about IPython at Sage Days at U. Washington, Seattle.
# Video credit: William Stein.
YouTubeVideo('MIAKOMzRl1I')
HTML
External sites
You can even embed an entire page from another site in an iframe; for example this is today's Wikipedia page for mobile users:
from IPython.display import HTML
HTML('<iframe src="http://www.damian.oquanta.info" width=600 height=400></iframe>')
SoundCloud
%load soundcloud.py
from IPython.display import HTML
h = HTML("""<iframe width="100%" height="166" scrolling="no" frameborder="no" src="https://w.soundcloud.com/player/?url=http%3A%2F%2Fapi.soundcloud.com%2Ftracks%2F94543639"></iframe>""")
display(h)
Latex
And we also support the display of mathematical expressions typeset in LaTeX, which is rendered
in the browser thanks to the MathJax library.
Here we are displaying the output of a Python computation as a LaTeX expression wrapped by the Math() object so the browser
renders it. The Math object will add the needed LaTeX delimiters ($$) if they are not provided:
from IPython.display import Math
Math(r'F(k) = \int_{-\infty}^{\infty} f(x) e^{2\pi i k} dx')
from IPython.display import Latex
Latex(r"""\begin{eqnarray}
\nabla \times \vec{\mathbf{B}} -\, \frac1c\, \frac{\partial\vec{\mathbf{E}}}{\partial t} & = \frac{4\pi}{c}\vec{\mathbf{j}} \\
\nabla \cdot \vec{\mathbf{E}} & = 4 \pi \rho \\
\nabla \times \vec{\mathbf{E}}\, +\, \frac1c\, \frac{\partial\vec{\mathbf{B}}}{\partial t} & = \vec{\mathbf{0}} \\
\nabla \cdot \vec{\mathbf{B}} & = 0
\end{eqnarray}""")
Local Files
The above examples embed images and video from the notebook filesystem in the output
areas of code cells. It is also possible to request these files directly in markdown cells
if they reside in the notebook directory via relative urls prefixed with files/:
files/[subdirectory/]<filename>
Linking to files and directories for viewing in the browser
It is also possible to link directly to files or directories so they can be opened in the browser. This is especially convenient if you're interacting with a tool within IPython that generates HTML pages, and you'd like to easily be able to open those in a new browser window. Alternatively, if your IPython notebook server is on a remote system, creating links provides an easy way to download any files that get generated.
As we saw above, there are a bunch of .ipynb files in our current directory.
ls
If we want to create a link to one of them, we can call use the FileLink object.
from IPython.display import FileLink
FileLink('IPython-powered_Slideshow_Reveal-ed.ipynb')
Alternatively, if we want to link to all of them, we can use the FileLinks object, passing '.' to indicate that we want links generated for the current working directory. Note that if there were other directories under the current directory, FileLinks would work in a recursive manner creating links to files in all sub-directories as well.
from IPython.display import FileLinks
FileLinks('.')
Loading external codes
- Drag and drop a
.pyin the dashboard - Use
%loadwith any local or remote url: the Matplotlib Gallery!
In this notebook we've kept the output saved so you can see the result, but you should run the next cell yourself (with an active internet connection).
Let's make sure we have pylab again, in case we have restarted the kernel due to the crash demo above
%pylab inline
%load http://matplotlib.sourceforge.net/mpl_examples/pylab_examples/integral_demo.py
#!/usr/bin/env python
# implement the example graphs/integral from pyx
from pylab import *
from matplotlib.patches import Polygon
def func(x):
return (x-3)*(x-5)*(x-7)+85
ax = subplot(111)
a, b = 2, 9 # integral area
x = arange(0, 10, 0.01)
y = func(x)
plot(x, y, linewidth=1)
# make the shaded region
ix = arange(a, b, 0.01)
iy = func(ix)
verts = [(a,0)] + list(zip(ix,iy)) + [(b,0)]
poly = Polygon(verts, facecolor='0.8', edgecolor='k')
ax.add_patch(poly)
text(0.5 * (a + b), 30,
r"$\int_a^b f(x)\mathrm{d}x$", horizontalalignment='center',
fontsize=20)
axis([0,10, 0, 180])
figtext(0.9, 0.05, 'x')
figtext(0.1, 0.9, 'y')
ax.set_xticks((a,b))
ax.set_xticklabels(('a','b'))
ax.set_yticks([])
show()
